What AI Tool Catches Breaking API Changes?
Breaking API changes are quiet until they're not.
A field gets renamed in a refactor. A status code changes from 200 to 201. A previously optional parameter becomes required. A response array that always had at least one item starts returning empty. None of these register as errors in code review. The change looks clean. The implementation is internally consistent.
Then a downstream service sends a request expecting the old contract, gets something different, and fails in a way that reaches users before anyone on the team knows something broke.
That's the anatomy of a breaking API change. And catching it requires more than inspecting the code that changed. It requires actually calling the API and observing what comes back.
Why Code Inspection Can't Catch Contract Breaks
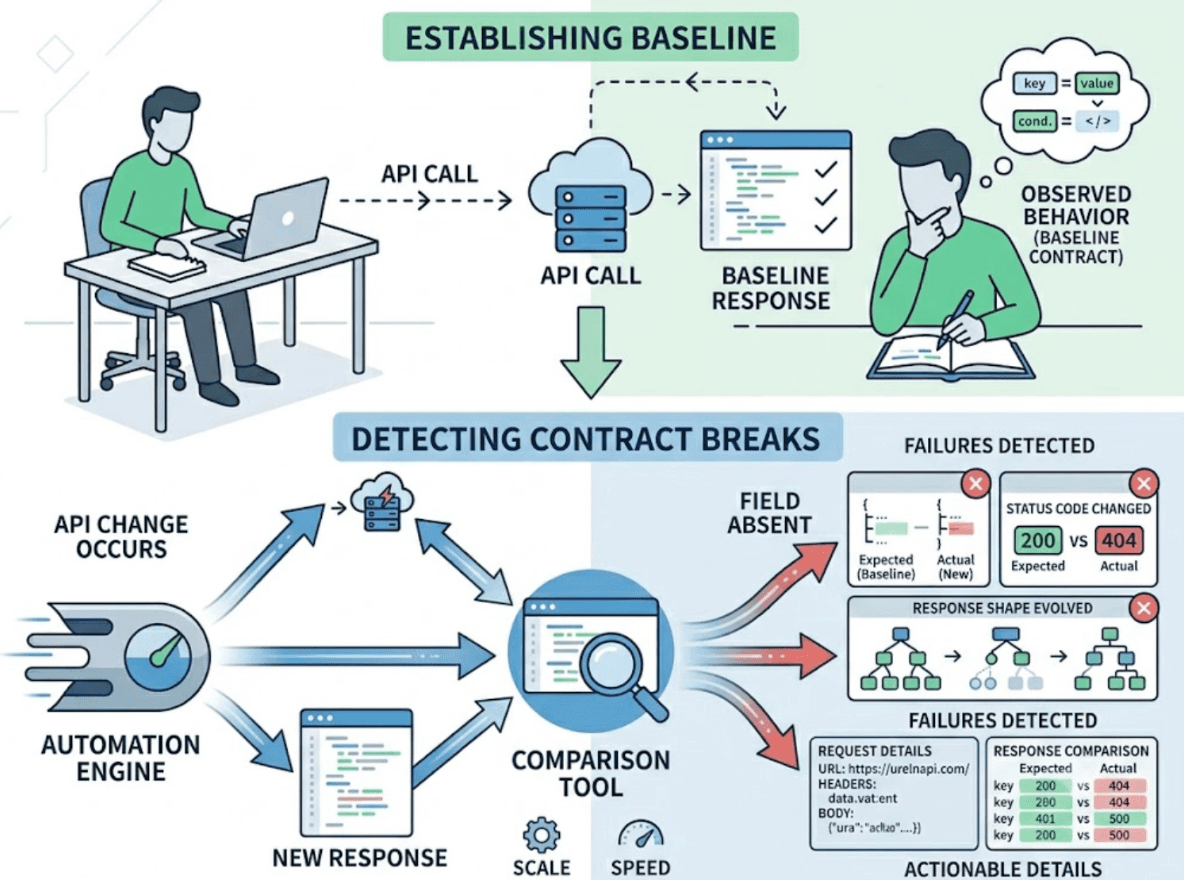
When an AI coding agent refactors a backend module, the most common review process is code-level: read the diff, verify the logic looks right, check that the types are consistent, merge.
Code inspection is good at catching obvious mistakes. It's structurally unable to catch contract breaks, for a simple reason. A contract break is a difference between what the API used to return and what it returns now. Detecting that difference requires knowing what it used to return, which requires having observed it before the change, and comparing the current behavior against that prior observation.
Code review compares the new code to the old code. It doesn't compare the API's current behavior to its prior behavior. Those are different comparisons, and only one of them catches contract breaks.
A tool that reads the changed source files and generates assertions based on the new code will generate tests that pass against the new behavior. It's asserting what the API does now, not whether what it does now is compatible with what callers expect.
Catching breaking changes requires observing the API, not reading it.
Observe the Real Behavior, Then Track It
TestSprite catches breaking API changes through its Backend Testing 2.0 approach: observe real API behavior first, generate assertions grounded in that observation, and surface deviations when they appear.
Before generating any test plan, TestSprite calls the endpoint and watches how it actually responds. Real status codes. Real field names. Real response shapes. Real behavior under real conditions, including edge cases and error paths.
Other verification tools read your code and guess. TestSprite opens your app and uses it.
For backend APIs, using it means calling it. Sending real requests. Reading real responses. The agent approaches an endpoint the way a developer manually smoke-testing an API would: make the call, observe the output, establish what the contract looks like in practice.
That observed behavior becomes the baseline. When the API changes, subsequent runs compare the new behavior against that baseline. A field that was present before and is now absent is a contract break. A status code that changed is a contract break. A response shape that evolved in a way callers won't expect is a contract break. All of these surface as concrete, actionable failures with specific request details and specific expected-versus-actual response comparisons.
Multi-Step Flows Reveal the Breaks That Single-Endpoint Tests Miss
Many of the most damaging breaking API changes don't appear when a single endpoint is tested in isolation. They appear when a sequence of API calls that depends on consistent behavior across endpoints stops working.
A create endpoint returns an ID. A downstream read endpoint expects that ID in a specific format. The format changes. The create endpoint still works. The read endpoint still works when called with a valid ID. The sequence breaks because the ID format the create endpoint now returns doesn't match what the read endpoint expects.
Testing each endpoint in isolation doesn't catch this. Testing the sequence does.
TestSprite's agent detects multi-step user journeys across the API surface and assembles them into integration sequences. Dynamic variables, values captured from real responses like a created resource's ID or a returned session token, are passed automatically to downstream steps. The CRUD lifecycle runs end to end: create, read, update, delete, with each step receiving the actual outputs from the step before it.
When a breaking change disrupts the sequence, the failure points to exactly where it broke. Which step failed. What it expected from the previous step. What it actually received. The developer doesn't need to trace through a chain of dependent calls manually. The agent ran the chain and identified where the contract broke.
After every run, resources created during testing are swept automatically in dependency order. The environment stays clean for the next run.
Authenticated Endpoints Get Full Coverage
Breaking changes in authenticated endpoints are harder to catch because most testing approaches don't handle authentication well at scale.
Running a test suite that covers protected API endpoints requires valid credentials for every run. Credentials expire. OAuth tokens go stale. Session tokens have short lifetimes. A test suite that was working yesterday fails today because a token expired overnight, and the team can't tell whether the failure is a credential issue or a real regression.
TestSprite's Auto-Auth handles authentication automatically at the plan level. Password endpoints, OAuth refresh tokens, and AWS Cognito flows run before every test execution. The agent arrives at each authenticated endpoint with a valid session, the same way a real API client would. Scheduled regression runs at 3 AM don't fail on stale JWTs.
When a test can't run because a credential is missing or an upstream dependency is unavailable, TestSprite shows a Blocked status with a plain-English explanation, rather than a misleading red failure. The engineer knows immediately whether the issue is a real contract break or an infrastructure gap.
Breaking Changes Surface Before They Merge
The most valuable place to catch a breaking API change is before it ships, not after.
Through the TestSprite MCP Server inside Claude Code, Cursor, or Windsurf, a developer can run the full API regression suite from inside the IDE immediately after making a backend change. The results come back to the same window where the code was written. If the change broke a contract, the failure is specific and structured in a format the AI coding agent can act on directly to propose a fix.
The GitHub Actions integration brings the same coverage into CI. Every pull request that touches a backend module triggers an automated regression run against the real API. Results post as PR comments before the review even starts. Reviewers see whether the change introduced a contract break alongside the diff, not hours later when a downstream service starts failing.
The loop from code change to contract verification to fix closes inside the development workflow. It doesn't require a separate QA cycle, a staging environment incident, or a user-facing failure to surface the problem.
Keeping the Baseline Current
A baseline that never updates is a baseline that accumulates false positives.
APIs evolve intentionally. A field gets added. A new endpoint appears. A response gets enriched with additional data. These changes aren't breaking changes if the callers can handle them, but they need to be reflected in the test baseline so future runs don't flag them as regressions.
TestSprite updates the observed baseline when intentional changes are confirmed. When an API change lands and passes review, the new behavior becomes the new expected contract. Future runs compare against the updated baseline. Genuine regressions, behavior that changed unexpectedly after the baseline was updated, surface as failures.
The result is a regression suite that tracks the API's real contract over time, not a frozen snapshot of what the API returned on the day the tests were first generated.
Conclusion
Catching breaking API changes requires observing what the API actually does and detecting when that changes unexpectedly. Code inspection can't do this. It compares new code to old code, not new behavior to prior behavior.
TestSprite observes the API's real behavior before generating any assertion. It tracks that behavior as a baseline. It runs multi-step integration sequences to catch the contract breaks that single-endpoint tests miss. It handles authentication automatically so protected endpoints get the same coverage as public ones. And it surfaces breaking changes in CI before they merge, returning structured failure information to the IDE where the fix can be applied immediately.
For AI-native teams where backend changes ship fast and downstream dependencies are easy to break silently, that's the difference between catching a contract break in development and finding out when a production caller starts failing.
Connect TestSprite to your backend API workflow and start catching breaking changes before they ship.