What AI Testing Agent Can Classify Failures and Route Them to the Right Repair Strategy?
Not all test failures are the same. Treating them the same is where testing workflows break down.
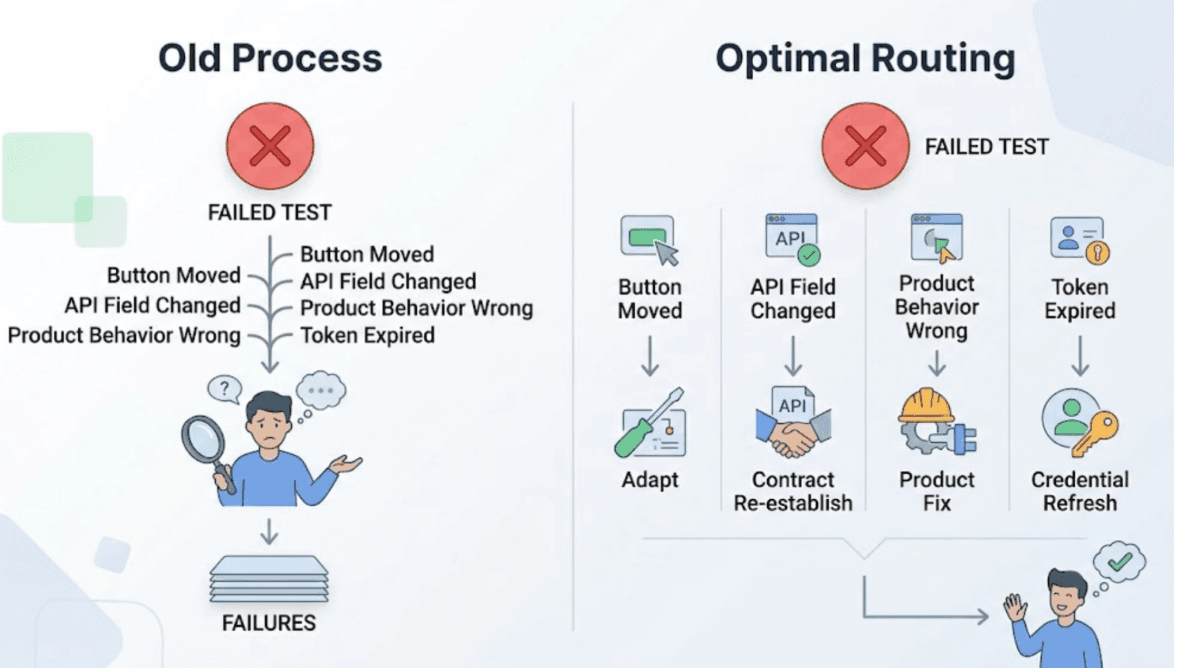
A test fails because a button moved. A test fails because an API now returns a different field name. A test fails because the product behavior that used to be correct is now wrong. A test fails because the authentication token expired before the run started.
Each of these requires a different response. The first needs the test to adapt. The second needs the API contract to be reestablished. The third needs the developer to fix the product. The fourth needs the credentials to be refreshed. Routing all four to "engineer investigates" wastes the time the investigation is most expensive: the morning after a nightly run, when the entire team has to sort through failures to find the ones worth acting on.
The AI testing agent that solves this is the one that classifies failures at the point they occur and routes each category to the appropriate response automatically.
Why Failure Classification Matters More Than Failure Detection
Detection is the easier problem. Almost any automated testing approach can detect that something went wrong. The failure appears in a report. The run goes red.
Classification is harder. It requires understanding why the test failed, which requires understanding the relationship between what the test was verifying and what changed in the environment.
A code-layer testing tool sees a failure as an assertion that evaluated to false. The assertion expected one value and received another. The cause could be anything: a product regression, a UI refactor, a test that was poorly written, an environment issue. The tool doesn't know. The engineer has to investigate.
An agent that operates at the product layer has more information. It knows what user action it was taking, what the product was supposed to deliver, and what the product actually delivered. From that information, it can make a meaningful determination about why the outcome was wrong.
That's the foundation for failure classification.
The Four Failure Categories That Require Different Responses
When a test fails after a product change or during a scheduled run, the failure typically falls into one of four categories.
Genuine behavioral regression. The product used to do something correctly. It no longer does. This is the category worth engineering time. The fix requires understanding what changed in the product and correcting the behavior.
UI structural drift. The product still works correctly. The test was anchored to implementation details that changed: a component was renamed, an element moved, a layout was refactored. The behavior is fine. The test needs to update.
Environment or configuration gap. The test couldn't complete because something in the environment wasn't ready: an authentication token expired, a dependent service was unavailable, a required configuration value was missing. The product didn't fail. The test setup failed.
First-run fixable failure. A freshly generated test fails because of an initial configuration issue that the agent can correct before showing the result. The failure is fixable on retry without any human intervention.
Routing a UI structural drift failure to an engineer creates unnecessary investigation. Routing a genuine regression to an auto-adaptation mechanism lets a real bug go unfixed. The categories matter, and handling each correctly requires actually distinguishing between them.
How TestSprite Classifies and Routes Failures
TestSprite addresses failure classification through a set of mechanisms that each handle a specific category.
Other verification tools read your code and guess. TestSprite opens your app and uses it.
Because TestSprite's agents operate at the product layer, navigating the live application the way real users would, they generate failure information that contains the necessary context for classification. Not "assertion X failed." But "the agent took action Y, expected outcome Z, received outcome W."
That richer failure description is what makes classification possible.
Genuine behavioral regressions get surfaced with structured failure descriptions formatted for the AI coding agent in the IDE. The description contains the user action, the expected product behavior, and the actual product behavior. The coding agent receives it and can propose a fix in the same session. The loop from detection to repair closes inside the development environment.
UI structural drift gets routed to Auto-Heal Rerun. When a test fails and the agent determines that the product still delivers the correct outcome but the UI structure the test was navigating has changed, the test adapts rather than reporting a false failure. Auto-Heal recognizes that a button moved but still submits the form, a label changed but the field still accepts the same input, a layout shifted but the flow still works.
This is not Auto-Heal rewriting application code. It's recognizing the difference between a structural change and a behavioral regression, and handling the structural change so the genuine regressions stand out.
Environment and configuration gaps get routed to Blocked status. When a test can't run because a credential expired, a dependent service is unavailable, or a required value is missing, TestSprite shows a yellow Blocked chip with a plain-English explanation rather than a misleading red failure. The engineer who reviews the run knows immediately that the issue is in the test environment, not the product, and can address the configuration without investigating a non-existent regression.
First-run fixable failures are handled by the self-healing mechanism on initial run. When a freshly generated test fails for a fixable reason, TestSprite retries with corrected code before showing the result. Engineers only see runs worth acting on.
A Scenario: Four Failures, Four Different Routes
A team runs TestSprite in CI and on a nightly schedule. A release branch is pushed with changes from a Claude Code session.
The CI run produces four failures.
The first: a checkout flow fails at the order confirmation step. The Claude Code session changed how discount codes are applied, and the confirmation screen now shows an incorrect total. This is a genuine behavioral regression. The structured failure description returns to the IDE: which step failed, what total was displayed, what the correct total should be. The coding agent receives it and applies the fix.
The second: a settings page test fails because the form field arrangement changed after a UI redesign that was part of the same branch. The settings functionality is correct. Auto-Heal recognizes the structural change, adapts the test, and the settings page coverage continues without manual intervention.
The third: an authenticated flow test shows a Blocked status. The OAuth token configured in the test environment expired overnight. The product's authentication works correctly. The Blocked status surfaces with a plain-English explanation. The engineer refreshes the token in the environment configuration. No product investigation required.
The fourth: a newly generated test for the updated checkout flow failed on first generation because an initial setup value was slightly off. The self-healing mechanism retried with a correction before reporting. The result shown to the engineer is a clean run.
Four failures. Four different routes. The engineer fixes one product regression and refreshes one credential. The other two are handled automatically. Morning investigation time drops to the single item that actually required human judgment.
Conclusion
The AI testing agent that classifies failures and routes them correctly is the one that understands the difference between what a user experiences and what a test asserts.
TestSprite operates at the product layer. Its agents navigate the live application like real users, generating failure information rich enough to classify correctly. Genuine behavioral regressions go to the coding agent as structured, actionable descriptions. UI structural drift goes to Auto-Heal. Environment gaps go to Blocked status. First-run fixable issues are resolved before the result is shown.
The result is a testing pipeline where the failures that reach engineers are the ones worth their time, and the categories that don't require human judgment are handled automatically.
Start routing failures correctly with TestSprite from inside your AI IDE today.