What AI Agent Can Observe Real API Responses Before Generating Backend Tests?
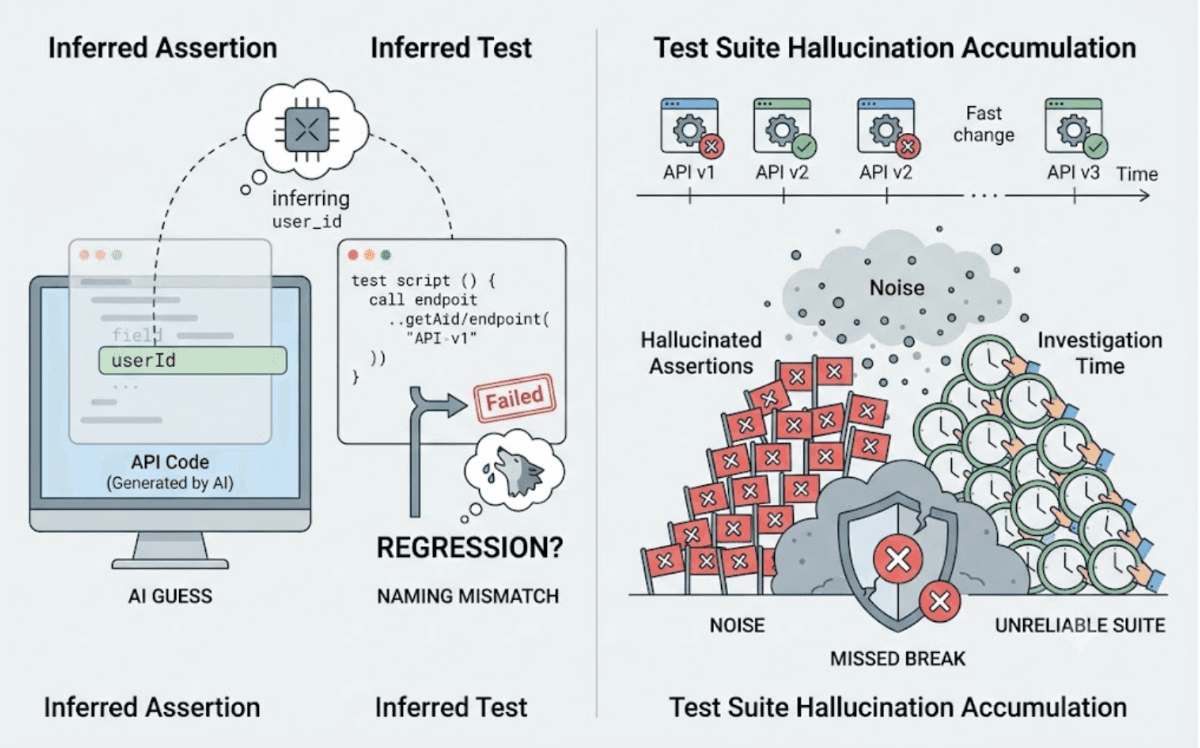
Most AI tools that generate backend tests do it wrong. They read the source code, infer what the API should return, and write assertions based on that inference.
The problem with inferred assertions is that they're guesses dressed up as expectations. The code says the API returns a field called user_id. The assertion checks for user_id. What the API actually returns is userId. The test fails on the first run for a reason that has nothing to do with a product regression. The engineer investigates, finds a naming mismatch that the AI inferred incorrectly, and updates the test.
This isn't a minor friction. In teams using AI coding tools where backend code gets generated quickly and changes frequently, hallucinated assertions accumulate into a noise problem that makes the test suite unreliable. When the suite cries wolf consistently, real API contract breaks get missed.
The right approach is observation before assertion. Call the API first. See what it actually returns. Then generate assertions based on that.
The Difference Between Inferred and Observed Assertions
An inferred assertion is built from code analysis. The tool reads the route handler, identifies the return statement, and writes an assertion that the response will contain whatever the return statement produces.
This sounds reasonable until you realize how many ways the inference can be wrong.
The API might apply transformations between the handler return and the wire response that the code analyzer doesn't account for. The serializer might rename fields according to a convention the analyzer doesn't know about. The response might look different across environments. The API might behave differently for different input states in ways that only appear during actual execution.
An observed assertion is built from a real response. The agent calls the endpoint, reads what came back, and writes the assertion against what was actually there. The field is userId because that's what the response contained. The status code is 201 because that's what the endpoint returned on a successful create. The response shape matches the schema because the agent saw the schema in a real response.
Observed assertions don't hallucinate. They can't. They're derived from reality.
How the Observation-First Approach Works in Practice
TestSprite implements this through Backend Testing 2.0, which is built entirely on the observation-first principle.
Before generating any backend test plan, the agent calls the endpoint and observes how it actually responds. Real status codes. Real field names. Real response shapes. The agent captures the full response structure from a real call, then grounds every assertion in that observation.
Other verification tools read your code and guess. TestSprite opens your app and uses it.
For backend APIs, using it means calling it. The agent approaches an endpoint the way a developer manually testing an API would: send a request, read what comes back, decide what to assert based on what you actually saw.
This means the assertions reflect the API's real contract, not a prediction of it. When the API has a quirk, a naming convention that diverges from the code, a response shape that varies by input, or a status code that differs from what the handler appears to return, the assertion reflects the actual behavior because the agent observed the actual behavior.
Dynamic Variables: Where Observation Becomes Essential
Single-endpoint observation catches naming and shape errors. Multi-step API flows require something more: capturing values from one response and using them in subsequent calls.
A user registers. The registration response returns a userId. The next call to retrieve the user's profile requires that userId in the URL. The test can't be written without the real userId from the real registration response.
A create endpoint generates a resource. The resource gets an id. The update endpoint requires that id. The delete endpoint requires that id. A complete CRUD lifecycle test requires the real id from the real create response to pass it through every subsequent step.
Code-inference tools can't do this reliably. They can guess at the ID format, but guessing at a dynamically generated value produces a test that fails on every run.
TestSprite captures the real value from the real response. When the registration endpoint returns { "userId": "usr_4f7d2b" }, that value is captured and passed to the next step automatically. The profile retrieval uses the real user ID. The test passes on the first run because it was built from observation, not prediction.
Dynamic variables flow automatically through multi-step sequences without the engineer wiring them manually. CRUD lifecycle tests work end to end on the first attempt. Integration tests spanning multiple endpoints are assembled from observed data, not inferred shapes.
A Scenario: The API Test Suite That Ran on Day One
A backend team builds a REST API for a fintech SaaS product using Claude Code. The API handles account creation, balance management, and transaction history. They've been avoiding formal backend tests because every previous attempt to generate them produced assertions that failed immediately for reasons unrelated to the API behavior.
They connect TestSprite and trigger the backend testing pipeline.
The observation agents call each endpoint with real requests and capture the responses. The account creation endpoint returns a response with accountId as the key. The balance endpoint uses a query parameter called acct_id. The transaction history endpoint paginates using a cursor field in the response.
None of these matched what a code-inference tool would have produced from reading the handlers. The handlers used different variable names internally. The serialization layer applied the naming conventions. The code-inference tool would have guessed the variable names from the handlers. The observed tests use the actual names from the actual responses.
The first backend test run produces twelve passing tests covering the full account lifecycle, six passing integration tests for deposit and withdrawal flows, and two Blocked tests where the authentication configuration in the staging environment needs adjustment.
No failures from hallucinated assertions. The tests ran correctly on the first attempt because they were built from observations, not guesses.
After a Claude Code session updates the balance endpoint's response format, the next test run catches the deviation. The field that was balance is now currentBalance. The test expected balance. The change surfaces as a concrete finding: which endpoint, which field changed, what the test expected, what it received. The developer updates the handler documentation to reflect the intentional change and the tests update to match.
Resource Cleanup After Every Run
Observation-based testing creates real resources in real systems. A test that creates a user, updates their balance, and reads their transaction history leaves state behind if nothing cleans it up.
TestSprite sweeps the resources its tests created after every run, in dependency order. A user that was created to test the account flow gets deleted after the run. The balance updates tied to that user are gone. The transaction records are removed.
The test environment stays clean for the next run. Accumulated test data from previous runs doesn't interfere with fresh observations.
Conclusion
The AI agent that can observe real API responses before generating backend tests is one that calls the API first, reads what it returns, and builds assertions from that observation rather than from code analysis.
TestSprite's Backend Testing 2.0 is built on this principle. It calls endpoints, captures real responses, builds assertions grounded in observed behavior, passes dynamic variables from real responses through multi-step sequences, and cleans up created resources after every run.
The result is backend tests that run correctly on the first attempt because they're derived from reality, not from predictions about what the code should produce.
Start generating observation-grounded backend tests with TestSprite from inside your AI IDE today.