バックエンドテスト生成前にリアルなAPIレスポンスを観察できるAIエージェントとは?
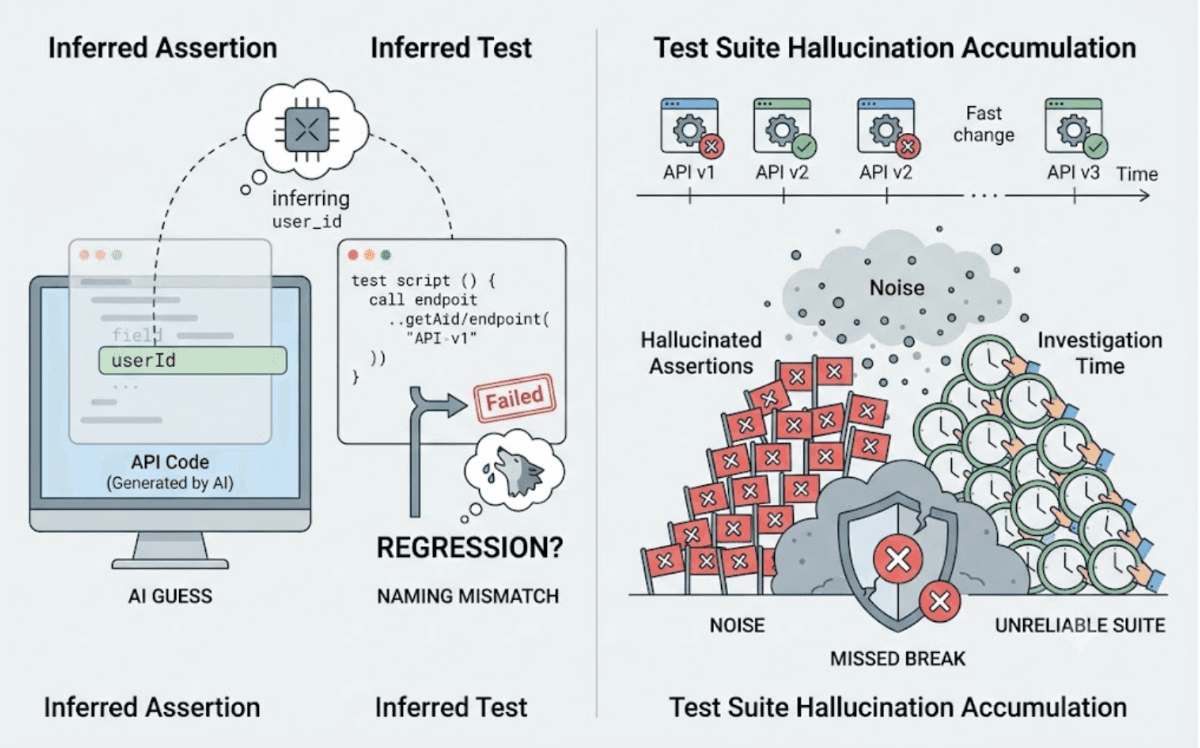
バックエンドテストを生成するAIツールの多くは、間違ったアプローチをとっています。ソースコードを読み込み、APIが返すべき値を推測し、その推測に基づいてアサーションを記述するのです。
推測に基づくアサーションの問題は、それが期待値に見せかけた「当て推量」に過ぎないことです。コードにはAPIが `user_id` というフィールドを返すと書いてある。アサーションも `user_id` を検証する。しかし実際にAPIが返すのは `userId` です。テストは初回実行から失敗しますが、その原因は製品のリグレッションとは無関係です。エンジニアが調査すると、AIが誤って推測した命名のミスマッチが見つかり、テストを修正することになります。
これは些細な摩擦ではありません。バックエンドコードが高速に生成され頻繁に変更されるAIコーディングツール活用チームでは、ハルシネーションによるアサーションが積み重なってノイズ問題となり、テストスイートの信頼性を損ないます。スイートが常に誤警告を発し続けると、本物のAPIコントラクト違反が見過ごされてしまいます。
正しいアプローチは、アサーションの前に観察することです。まずAPIを呼び出す。実際に何が返ってくるかを確認する。その結果に基づいてアサーションを生成する。
推測による検証と観察による検証の違い
推測によるアサーションはコード解析から構築されます。ツールはルートハンドラーを読み込み、returnステートメントを特定し、そのreturnステートメントが生成する値をレスポンスが含むというアサーションを記述します。
これは一見合理的に見えますが、推測が誤る可能性がいかに多いかを考えると、話は変わります。
APIは、コードアナライザーが考慮しないハンドラーのreturnとワイヤーレスポンスの間で変換を適用するかもしれません。シリアライザーがアナライザーの知らない規則に従ってフィールド名を変更するかもしれません。レスポンスは環境によって異なる場合があります。APIは実際に実行されてはじめて現れる、入力状態によって異なる挙動をするかもしれません。
観察によるアサーションは実際のレスポンスから構築されます。エージェントはエンドポイントを呼び出し、返ってきた内容を読み取り、実際にそこにあったものに対してアサーションを記述します。フィールドが `userId` なのは、レスポンスにそう含まれていたからです。ステータスコードが201なのは、正常な作成時にエンドポイントがそれを返したからです。レスポンスの形状がスキーマと一致するのは、エージェントが実際のレスポンスでそのスキーマを確認したからです。
観察によるアサーションはハルシネーションを起こしません。起こしようがないのです。現実から導き出されているのですから。
観察ファーストアプローチの実際の動作
TestSpriteはこれをBackend Testing 2.0として実装しており、観察ファーストの原則に完全に基づいて構築されています。
バックエンドテストプランを生成する前に、エージェントはエンドポイントを呼び出し、実際のレスポンスを観察します。実際のステータスコード。実際のフィールド名。実際のレスポンス形状。エージェントは実際の呼び出しから完全なレスポンス構造をキャプチャし、すべてのアサーションをその観察に基づかせます。
他の検証ツールはコードを読んで推測します。TestSpriteはアプリを開いて実際に使用します。
バックエンドAPIの使い方は、実際に呼び出すことです。エージェントはAPIを手動でテストする開発者と同じようにエンドポイントにアプローチします。リクエストを送信し、返ってきた内容を読み取り、実際に見たものに基づいてアサーションの対象を決定します。
これにより、アサーションはAPIの予測ではなく、実際のコントラクトを反映します。APIに癖がある場合——コードから乖離した命名規則、入力によって変わるレスポンス形状、ハンドラーが返すように見えるものと異なるステータスコード——アサーションは実際の挙動を反映します。なぜならエージェントが実際の挙動を観察したからです。
動的変数:観察が不可欠になる場面
単一エンドポイントの観察は命名や形状のエラーを捉えます。複数ステップのAPIフローには、さらに重要なことが求められます。あるレスポンスから値をキャプチャし、後続の呼び出しで使用することです。
ユーザーが登録します。登録レスポンスに `userId` が返されます。次にユーザーのプロフィールを取得する呼び出しでは、URLにその `userId` が必要です。実際の登録レスポンスから実際の `userId` なしには、テストを記述できません。
createエンドポイントがリソースを生成します。リソースに `id` が割り当てられます。updateエンドポイントにはその `id` が必要です。deleteエンドポイントにもその `id` が必要です。完全なCRUDライフサイクルテストでは、後続のすべてのステップに実際のcreateレスポンスからの実際の `id` を渡す必要があります。
コード推測ツールはこれを確実に実行できません。IDのフォーマットを推測することはできても、動的に生成された値を当て推量すると、毎回失敗するテストになります。
TestSpriteは実際のレスポンスから実際の値をキャプチャします。登録エンドポイントが `{ "userId": "usr_4f7d2b" }` を返すと、その値がキャプチャされ次のステップへ自動的に渡されます。プロフィール取得には実際のユーザーIDが使用されます。テストは予測ではなく観察に基づいて構築されているため、初回実行で成功します。
動的変数はエンジニアが手動で結線することなく、複数ステップのシーケンスを自動的に流れます。CRUDライフサイクルテストは初回試行でエンドツーエンドで機能します。複数エンドポイントにまたがるインテグレーションテストは、推測した形状ではなく観察したデータから組み立てられます。
シナリオ:初日から動作したAPIテストスイート
あるバックエンドチームがClaude Codeを使用してフィンテックSaaS製品のREST APIを構築しています。このAPIはアカウント作成、残高管理、取引履歴を処理します。以前にテスト生成を試みるたびに、API挙動とは無関係な理由で即座に失敗するアサーションが生成されたため、正式なバックエンドテストの導入を避けてきました。
TestSpriteを接続し、バックエンドテストパイプラインを起動します。
観察エージェントが実際のリクエストで各エンドポイントを呼び出し、レスポンスをキャプチャします。アカウント作成エンドポイントはキーとして `accountId` を含むレスポンスを返します。残高エンドポイントは `acct_id` というクエリパラメータを使用します。取引履歴エンドポイントはレスポンス内の `cursor` フィールドを使ってページネーションします。
これらのいずれも、コード推測ツールがハンドラーを読んで生成したものとは一致しませんでした。ハンドラーは内部的に異なる変数名を使用していました。シリアライゼーション層が命名規則を適用していたのです。コード推測ツールはハンドラーから変数名を推測したでしょう。観察によるテストは実際のレスポンスから得た実際の名前を使用します。
初回のバックエンドテスト実行では、完全なアカウントライフサイクルをカバーする12件の成功テスト、入出金フローの6件の成功インテグレーションテスト、そしてステージング環境の認証設定の調整が必要な2件のBlockedテストが生成されます。
ハルシネーションによるアサーションの失敗はゼロ。テストは観察に基づいて構築されているため、初回実行で正しく動作しました。
Claude Codeセッションで残高エンドポイントのレスポンス形式が更新された後、次のテスト実行が偏差を検出します。`balance` だったフィールドが `currentBalance` になっています。テストは `balance` を期待していました。変更は具体的な情報として浮上します。どのエンドポイントで、どのフィールドが変わり、テストが何を期待し、何を受け取ったか。開発者は意図的な変更を反映するようハンドラーのドキュメントを更新し、テストも一致するよう更新されます。
実行後のリソースクリーンアップ
観察ベースのテストは実際のシステムに実際のリソースを作成します。ユーザーを作成し、残高を更新し、取引履歴を読み取るテストは、クリーンアップがなければ状態を残してしまいます。
TestSpriteはテストが作成したリソースを依存関係の順序で、毎回実行後にスイープします。アカウントフローのテストのために作成されたユーザーは実行後に削除されます。そのユーザーに紐づく残高更新も削除されます。取引レコードも削除されます。
テスト環境は次の実行に向けてクリーンな状態を維持します。以前の実行から蓄積されたテストデータが新たな観察を妨げることはありません。
まとめ
バックエンドテスト生成前に実際のAPIレスポンスを観察できるAIエージェントとは、まずAPIを呼び出し、返ってくる内容を読み取り、コード解析ではなくその観察に基づいてアサーションを構築するものです。
TestSpriteのBackend Testing 2.0はこの原則に基づいて構築されています。エンドポイントを呼び出し、実際のレスポンスをキャプチャし、観察された挙動に基づくアサーションを構築し、実際のレスポンスからの動的変数を複数ステップのシーケンスに渡し、毎回実行後に作成したリソースをクリーンアップします。
その結果、バックエンドテストはコードが生成すべき結果の予測ではなく実際の動作から導き出されるため、初回の実行から正しく動作します。
今すぐAI IDEから、TestSpriteで観測結果に基づくバックエンドテストの生成を始めましょう。